Researchers from the Ontology Engineering Group (OEG) (member of the MoviTUR Cluster) have written an article to be published in December 2020 in the Journal of Web Semantics Volume 65. This publication is related to BigData & Intelligent Transportation Systems and Traffic & Public Transport Management cluster’s research lines. You can find the abstract and a link to the full article below.
Investigadores del Ontology Engineering Group (OEG), miembro del clúster MoviTUR, han escrito un artículo que va a ser publicado en Diciembre de 2020 en Volumen 65 de la revista Journal of Web Semantics. Esta investigación forma parte de las líneas de investigación del clúster sobre BigData y Sistemas Inteligentes de Transporte y Gestión del Tráfico y el Transporte Público. A continuación el abstract y el acceso a completo al artículo.
Abstract
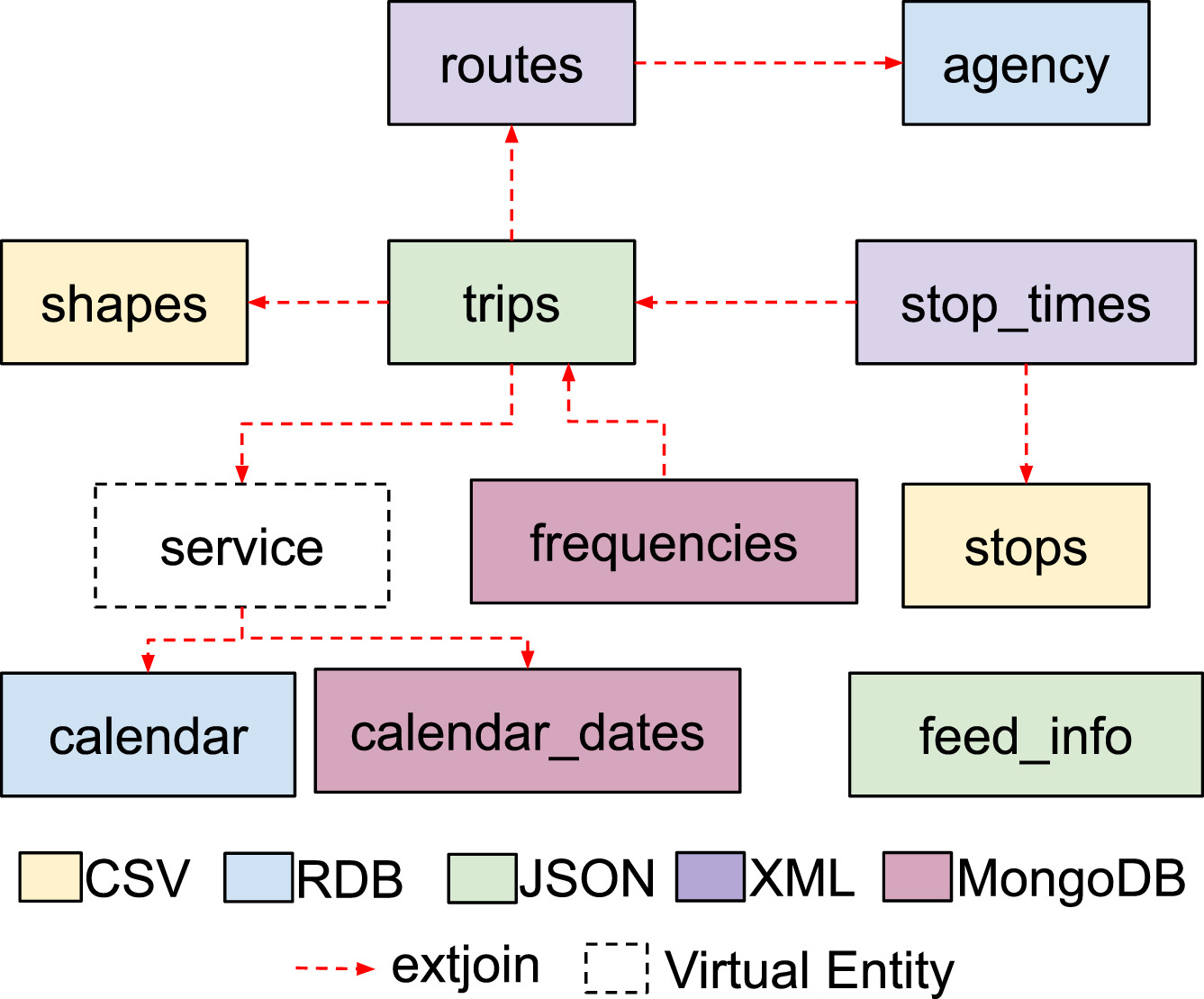
A large number of datasets are being made available on the Web using a variety of formats and according to diverse data models. Ontology Based Data Integration (OBDI) has been traditionally proposed as a mechanism to facilitate access to such heterogeneous datasets, providing a unified view over their data by means of ontologies. Recently, the term “Virtual Knowledge Graph Access” has begun to be used to refer to the mechanisms that provide query-based access to knowledge graphs virtually generated from heterogeneous data sources. Several OBDI engines exist in the state of the art, with overlapping capabilities but also clear differences among them (in terms of the data formats that they can deal with, mapping languages that they support, query expressivity that they allow, etc.). These engines have been evaluated with different testbeds and benchmarks. However, their heterogeneity has made it difficult to come up with a common comprehensive benchmark that allows for comparisons among them to facilitate their selection by practitioners, and more importantly, for their continuous improvement by the teams that maintain them. In this paper we present GTFS-Madrid-Bench, a benchmark to evaluate OBDI engines that can be used for the provision of access mechanisms to virtual knowledge graphs. Our proposal introduces several scenarios that aim at measuring the query capabilities, performance and scalability of all these engines, considering their heterogeneity. The data sources used in our benchmark are derived from the GTFS data files of the subway network of Madrid. They have been transformed into several formats (CSV, JSON, SQL and XML) and scaled up. The query set aims at addressing a representative number of SPARQL 1.1 features while covering usual queries that data consumers may be interested in.


